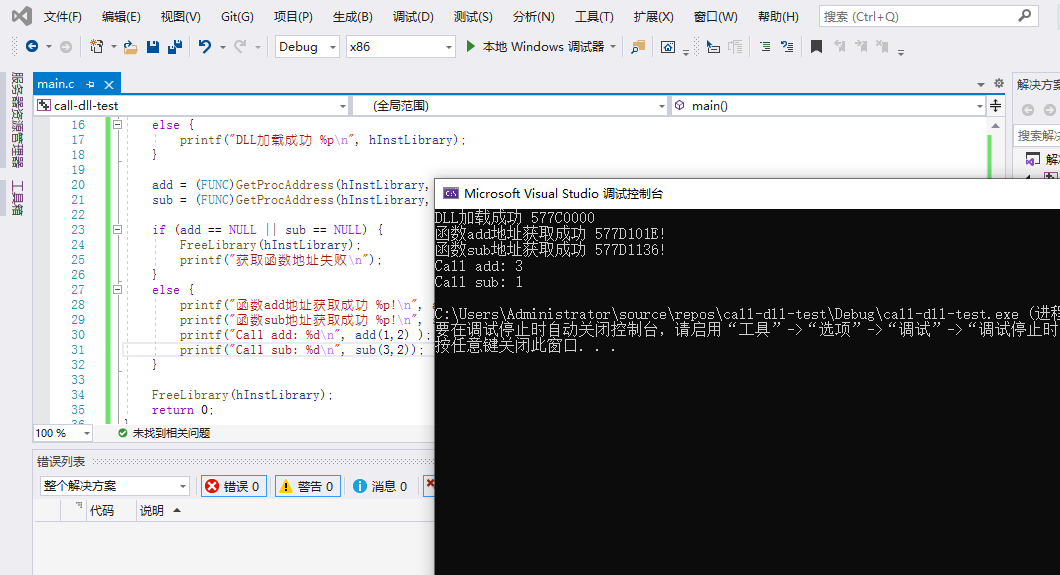
intmain(){ int m, n; printf("Input two numbers: "); scanf("%d %d", &m, &n); printf("%d+%d=%d\n", m, n, add(m, n)); printf("%d-%d=%d\n", m, n, sub(m, n)); return0; }
编译生成main:
1
gcc main.c testlib.so -o main
生成之后如果直接执行main会报错:
1
./main: error while loading shared libraries: testlib.so: cannot open shared object file: No such file or directory
因为此时系统不知道应该从哪里加载testlib.so:
1 2 3 4 5 6
chorder@debian:~/testlib$ldd main linux-vdso.so.1 (0x00007fff979c7000) testlib.so => not found libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007fa0e5d8c000) /lib64/ld-linux-x86-64.so.2 (0x00007fa0e5f70000)
//使用库文件中的函数实现相关功能 printf("Input two numbers: "); scanf("%d %d", &m, &n); printf("%d+%d=%d\n", m, n, add(m, n)); printf("%d-%d=%d\n", m, n, sub(m, n)); //关闭库文件 dlclose(handler); return0; }
funcinit(){ fmt.Printf("\nchorder.net/example/src2.go init() has been called.") }
funcSrc2(){ fmt.Printf("\nchorder.net/example/src2.go Src1() has been called.") }
编写代码调用这两个包中的方法:
packge_test.go
1 2 3 4 5 6 7 8
package main
import"chorder.net/example"
funcmain(){ example.Src1() example.Src2() }
执行结果:
1 2 3 4 5 6
>go run packge_test.go
chorder.net/example/src1.go init() has been called. chorder.net/example/src2.go init() has been called. chorder.net/example/src1.go Src1() has been called. chorder.net/example/src2.go Src1() has been called.
Entering discovery mode for 'upnp:rootdevice', Ctl+C to stop...
**************************************************************** SSDP reply message from 192.168.1.1:49652 XML file is located at http://192.168.1.1:49652/49652gatedesc.xml Device is running Linux/3.10.53-HULK2, UPnP/1.0, Portable SDK for UPnP devices/1.6.25 ****************************************************************
^C Discover mode halted...
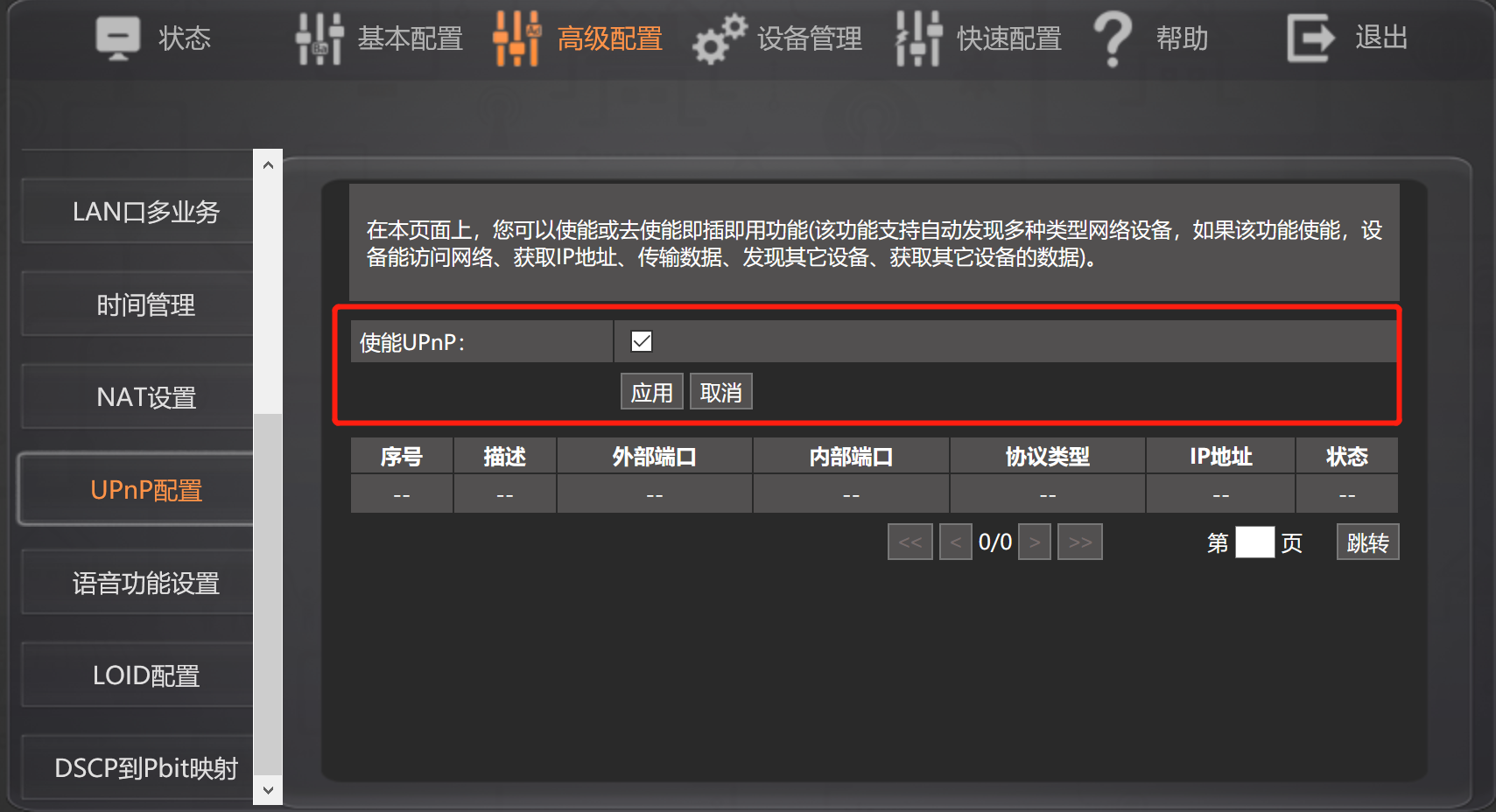
此时已经获得Gateway中的SSDP描述文件,Ctrl-C停止SSDP搜寻。
执行host list,列出扫描到的主机,并执行host get 0选中主机0(Gateway):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
upnp> host list
[0] 192.168.1.1:49652
upnp> host get 0
Requesting device and service info for 192.168.1.1:49652 (this could take a few seconds)...