!
!
建立热点:
@echo off
netsh wlan set hostednetwork mode=allow
netsh wlan set hostednetwork ssid=热点名 key=密码
netsh wlan start hostednetwork
关闭热点
netsh wlan set hostednetwork mode=disallow
最近在研究二进制,研究到函数调用部分,将自己理解的原理做个记录。
首先需要了解系统栈的工作原理,栈可以理解成一种先进后出的数据结构,这就不用多说了。
在操作系统中,系统栈也起到用来维护函数调用、参数传递等关系的一个作用。嗯,这是我的理解。
在高级语言编程中,函数调用的底层原理是对用户屏蔽的,所以不用过多的纠结于底层的实现。而对于
汇编研究者来说,了解这个原理就很重要了。
首先可以想象一下,汇编语言在内存中是以指令的形式存在的,这些指令是按照顺序存储和执行的,高级语言中
编写的循环、调用,到了底层都会变成一些最基本的判断和跳转,如何在线性的结构上完成“非线性”的过程调度,
理解了这些,就理解了汇编。
这里先抛出高级语言的一个例子:
1 | /*20160701*/ |
在这个程序中,main函数调用了函数funcA,funcA对传入的数据进行+1然后返回。
这个程序在编译之后,main函数变成这样:
1 | (gdb) disassemble main |
其中rbp是调用main函数的函数的栈桢的底部,这么说有点绕,简单的来说,main函数调用了funcA,那funcA中首先要做的一件事情就是把调用它的main函数栈桢的底部保存,所以在main函数被操作系统装载执行之后,main要做的首先是把调用它的函数的栈桢的底部保存,不然怎么返回呢?
第二个步骤把rsp的值传递给rbp,这是替换当前栈桢的底部,因为调用了funcA,所以要为funcA创建独立的栈桢,于是抬高栈底,怎么抬高呢,把栈顶传给指向栈桢底部的指针就可以了。
下一步是抬高栈顶,这是为funcA创建栈桢空间。
接着将参数传递给edi,因为这里只有一个参数,所以不涉及到参数顺序的问题,关于这个问题,可以去了解一下函数调用约定
调用了funcA,再来观察一下funcA的内部机制:
1 | (gdb) disassemble funcA |
同样的,在funcA中,首先保存上一个函数,即main函数栈桢的栈底,然后将rsp的值赋给rbp,抬高栈桢底部。
接着从edi中取得参数,并放入位于自身栈桢空间中,rbp之后的双字单元内。
然后执行操作,将其自增。
执行完成之后,将返回值保存在eax中,等待返回。
弹出上一个函数的栈桢的底部,重新回到main函数的空间。
PS:
直到目前为止,这个程序反编译出来的结果和书上说的原理还是有一些出入的,还有下面几个问题:
0x01 书上说的是,传递参数,会将参数按照一定顺序压栈,而不是像本程序中这样使用edi
0x02 在main函数调用funcA函数之后,将栈顶指针esp抬高了,但是在funcA函数执行完成需要返回到main函数的时候,只恢复了ebp指针,并没有恢复esp指针,这是为什么?
希望接下来可以搞懂上面的两个问题。
本文中用到的相关代码:
1 | /*20160701*/ |
转载自 http://www.tsingfun.com/html/2015/dev_0804/hello_os_word_my_first_os.html
首先阐述下程序运行的基本原理:计算机CPU只执行二进制指令,我们使用的开发语言开发出的程序最终由相应的编译器编译为二进制指令,二进制中包含程序相关的数据、代码指令(用我们最常见的公式描述就是:程序=数据+算法)。CPU读取相应的指令、数据后开始执行,执行后的结果输出到外部设备,如屏幕、磁盘等。整个过程中,CPU发挥最为核心的作用,与其他设备一起完成程序的执行、输出。
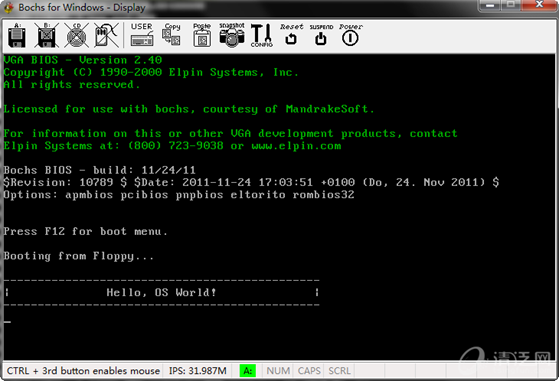
OS本身也是程序,它的运行也是如此,开机后从指定地址处(0x7c00),开始执行指令。先看看本节例子最终运行效果:
编译运行环境:
nasm:Inter x86汇编编译工具,用户将我们的汇编代码编译为二进制。
(下载地址 http://www.tsingfun.com/html/2015/soft_0804/nasm_asm.html)
Bochs:运行os的虚拟机工具,模拟加载我们生成的软盘映像,并运行os。
(下载地址 http://www.tsingfun.com/html/2015/soft_0804/Bochs_Lightweight_VirtualMachine.html)
代码如下:
1 | ;-------------------------------------------------------------- |
其中,主要的步骤代码中都有详尽的注释,如有任何问题,请移步至论坛《深入OS》板块发帖讨论。
编译执行过程:
打开dos窗口,进入源码所在目录,执行命令nasm boot.asm -o pfos.img:

同目录下生成一个”pfos.img”软盘映像文件,接下来只需要把它装载到虚拟机运行即可,当然有条件的话可以实际写入老式的软盘用真机运行,结果是一样的。
同目录下新建一个 pfos.bxrc Bochs配置文件,内容如下:
1 | #how much memory the emulated machine will have |
双击“pfos.bxrc”启动Bochs运行即可启动我们自己写的os了。
源码下载:http://www.tsingfun.com/uploadfile/2016/0628/hello os world.zip
接下来解释一下运行原理:
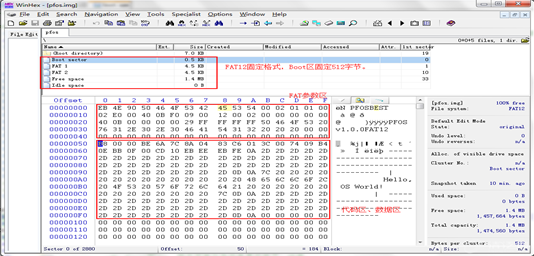
首先,软盘大小是1.44M(这个是固定的),所以我们在程序中指定它为1,474,560 字节,除了程序本身的指令、数据外,不足的部分全部补零。
TIMES 1469432 DB 0 就是此处开始写1469432个字节的0。
软盘采用的是FAT12文件格式,我们现在的常见的文件格式有FAT32、NTFS、EXT3等,FAT12是早期的一种文件格式。文件格式是文件格式化存储的一种算法,比如我们要将一个文件存储到软盘(磁盘)上,有些人可能会想我直接从地址0开始存储,直到结束,那么文件名、文件大小、创建时间等其他信息怎么存?紧接着后面继续存储么?那该给各部分分配多少字节空间?先不说后续查找文件的效率,这种存储方法无章可循会完全失控,是不行的方案。
文件格式化算法就解决了此类问题,而且兼顾文件的高效率查找。基本原理就是给软盘(磁盘)分区:FAT区、目录区、数据区,存储文件时先存储文件基本信息到目录区,然后文件的数据按照一定格式存储到数据区,目录区中有数据区中文件数据的地址。
这里只简单介绍一下FAT12格式,后续篇章会深入解析每个字节代表的含义。
我们来看看我们生成的映像里面到底有什么东西?这时我们需要用到二进制查看工具WinHex,点此下载 http://www.tsingfun.com/html/2015/soft_0804/WinHex.html 。
以上看到的是二进制静态代码,实际运行中各指令的地址都是动态变化的,下来一起借助Bochs的debug功能来一探究竟。
我们双击“pfos.bxrc”默认是以运行模式启动Bochs,实际上我们应该启动bochsdbg.exe,因此写个简单的批处理脚本启动它吧,如下:
1 | @echo off |
双击脚本,启动debug模式,如下:
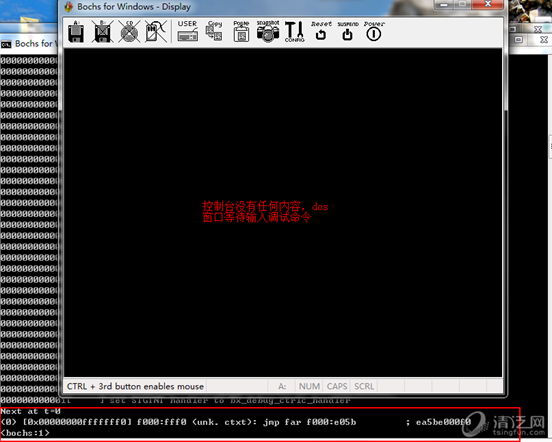
Bochs常用的debug命令如下:
1 | b 0x... 断点命令,指定地址处调试 |
大家有兴趣的话可以调试下,然后看看每步骤寄存器值的变化。
总结:本篇主要是让大家对操作系统有个整体概念上的认识,揭开os神秘的面纱,从底层调试到运行,每个过程都真真切切展现在大家面前。至于汇编指令、地址寻址暂时不懂的话,也不要紧,后续章节会继续作详细阐述,力求使大家在不断的运行、调试过程中逐渐熟悉并掌握汇编及计算机底层技术。
本次的编程环境: CentOS 6.8
Linux centos 2.6.32-573.8.1.el6.x86_64
在内核的源代码中定义了很多进程和进程调度相关的内容。其实Linux内核中所有关于进程的表示全都放在“进程描述符”这个庞大的结构体当中,关于这个结构体的内容和定义,可以在内核的linux/sched.h文件中找到。
现在就来通过编程实现对进程描述符的操作,主要是读取。至于修改等操作,将在后面的内容中提到。
通过对进程描述符的读取,可以获取进程的一切内容,包括进程的ID,进程的地址空间等等。
不多说,上代码:
1 | //20160912 |
以上的代码,主要就是通过引入内核头文件,进而引用进程描述符中的指针,并通过这种方式获取当前进程和相关进程的描述信息。
Makefile文件如下:
1 | #Makefile |
编译的指令:
1 | make -C /usr/src/linux SUBDIRS=$PWD modules |
然后通过insmod把模块装载进内核,首先tty输出了Hello tty!
同时在/var/log/message中,模块打印出了这些内容:
1 | Sep 12 10:35:36 centos kernel: Hello -- from the kernel... |
分别是这个进程的相关信息。
对于进程描述符的定义,在本次实验用来编译的内核源码包(kernel-devel-2.6.32-642.4.2.el6.x86_64)中,
进程描述符具体定义在include/linux/sched.h的1326行往后。
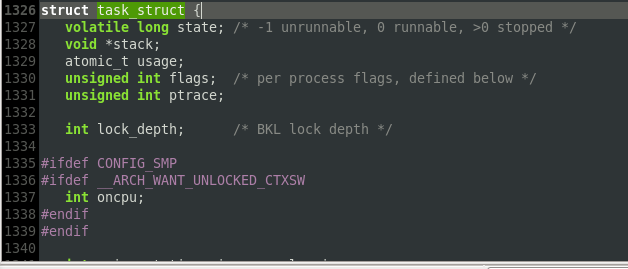
需要参考的进程具体信息都在其中,可随时参考,以备不时之需。
Linux内核编程一直是我很想掌握的一个技能。如果问我为什么,我也说不上来。
也许是希望有一天自己的ID也出现在内核开发组的邮件列表里?或是内核发行文件的CREDITS文件上?
也许是吧。其实更多的,可能是对于底层的崇拜,以及对于内核的求索精神。
想到操作系统的繁杂,想到软件系统之间的衔接,内心觉得精妙的同时,更是深深的迷恋。
所以从这篇文章开始,我要真正的走进Linux内核里了,让代码指引我,去奇妙的世界一探究竟。
在这篇文章中,一起来对内核说Hello World。
本次的编程环境:
CentOS 6.8
Linux centos 2.6.32-573.8.1.el6.x86_64
没有安装内核的,可能需要安装一下内核源码包
kernel-devel-2.6.32-642.4.2.el6.x86_64
1 | yum install kernel-devel-2.6.32-642.4.2.el6.x86_64 |
安装好之后,这个版本内核可以在/usr/src/linux找到。
然后先话不多说,首先看代码。
1 | //20160904 |
以上代码是kernel_hello_world.c内容。
作为内核模块,在编译的时候,Makefile文件这样写:
1 | #File:Makefile |
然后可以通过这条命令来编译:
1 | make -C /usr/src/linux SUBDIRS=$PWD modules |
编译好以后,目录下面的文件可能是这样子:
1 | kernel_hello_world.ko.unsigned kernel_hello_world.o Module.symvers |
有这么多文件被生成,其中kernel_hello_world.ko就是本次编译出来的内核模块文件,在Linux内核中有很多这样的模块,它们可能充当着不同的角色,可能是驱动,也可能是各种设备。
这个模块会在/var/log/message文件中打印一行字,即Hello,World! --from the kernel space...
可以使用insmod kernel_hello_world.ko来将这个模块载入到内核。
使用lsmod来查看是否已经加载。
使用rmmod kernel_hello_world.ko来卸载这个模块。
可以tail /var/log/message来看一下是否成功执行了呢?
Hello,Kernel.

VmWare默认的镜像格式是.vmdk格式的,VirtualBox则默认是.vdi格式的。其实这在VirtualBox新建虚拟机的过程中是可选的。
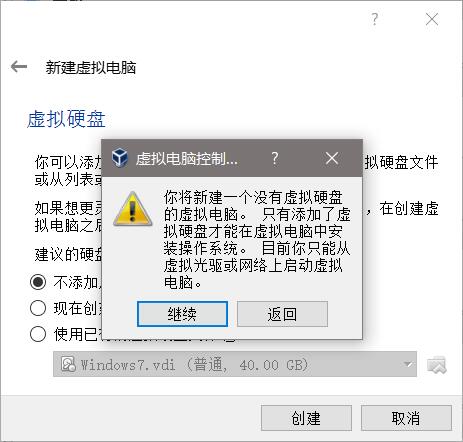
导入.vmdk格式的镜像到VirtualBox只需要新建一个虚拟机,并且不创建虚拟硬盘。如下图:
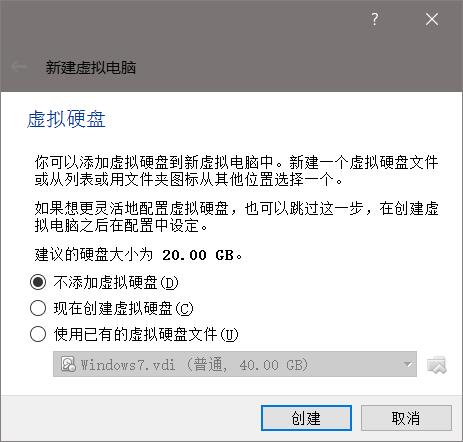
无视警告,继续:
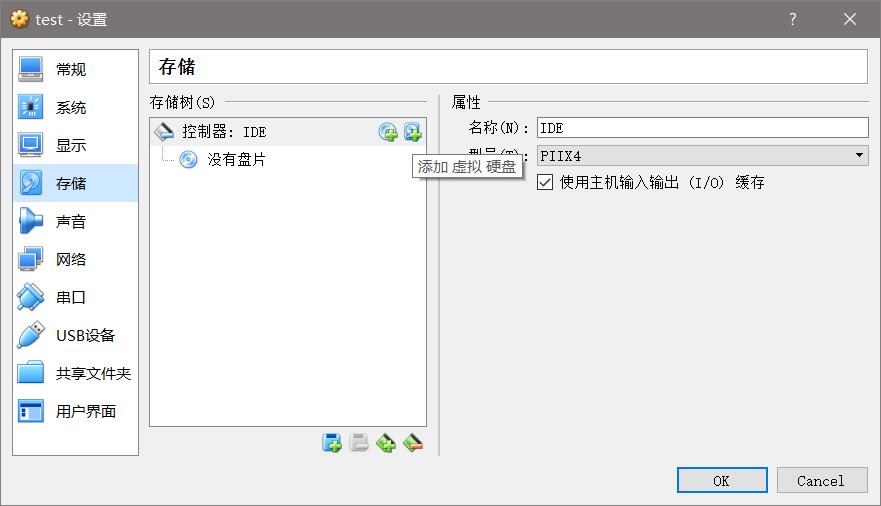
创建好之后,在设置里面把.vmdk格式的虚拟硬盘添加进去:
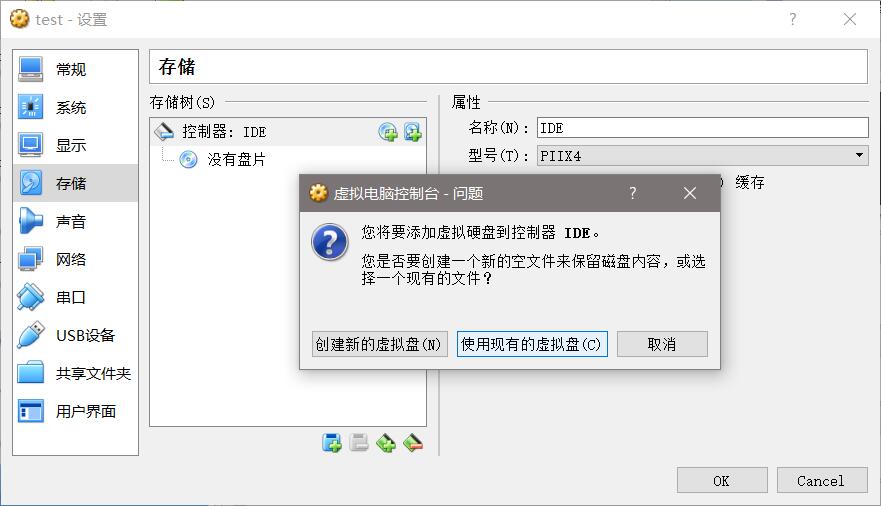
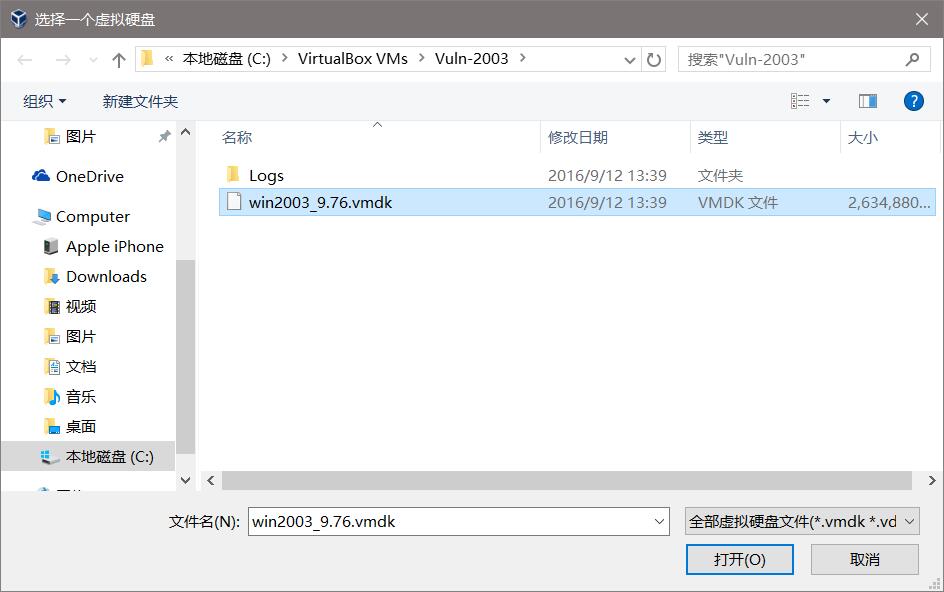
这样就可以了。
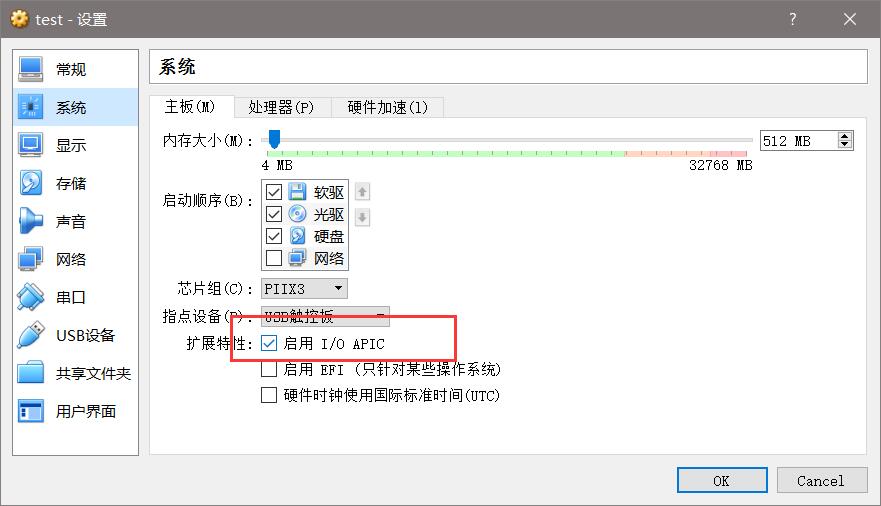
如果遇到windows虚拟机起不开的情况,尝试更改下下面这个选项:
启用下I/O APIC试试。

最近在研究二进制,研究到函数调用部分,将自己理解的原理做个记录。
首先需要了解系统栈的工作原理,栈可以理解成一种先进后出的数据结构,这就不用多说了。
在操作系统中,系统栈也起到用来维护函数调用、参数传递等关系的一个作用。嗯,这是我的理解。
在高级语言编程中,函数调用的底层原理是对用户屏蔽的,所以不用过多的纠结于底层的实现。而对于
汇编研究者来说,了解这个原理就很重要了。
首先可以想象一下,汇编语言在内存中是以指令的形式存在的,这些指令是按照顺序存储和执行的,高级语言中
编写的循环、调用,到了底层都会变成一些最基本的判断和跳转,如何在线性的结构上完成“非线性”的过程调度,
理解了这些,就理解了汇编。
这里先抛出高级语言的一个例子:
1 | /*20160701*/ |
在这个程序中,main函数调用了函数funcA,funcA对传入的数据进行+1然后返回。
这个程序在编译之后,main函数变成这样:
1 | (gdb) disassemble main |
其中rbp是调用main函数的函数的栈桢的底部,这么说有点绕,简单的来说,main函数调用了funcA,那funcA中首先要做的一件事情就是把调用它的main函数栈桢的底部保存,所以在main函数被操作系统装载执行之后,main要做的首先是把调用它的函数的栈桢的底部保存,不然怎么返回呢?
第二个步骤把rsp的值传递给rbp,这是替换当前栈桢的底部,因为调用了funcA,所以要为funcA创建独立的栈桢,于是抬高栈底,怎么抬高呢,把栈顶传给指向栈桢底部的指针就可以了。
下一步是抬高栈顶,这是为funcA创建栈桢空间。
接着将参数传递给edi,因为这里只有一个参数,所以不涉及到参数顺序的问题,关于这个问题,可以去了解一下函数调用约定
调用了funcA,再来观察一下funcA的内部机制:
1 | (gdb) disassemble funcA |
同样的,在funcA中,首先保存上一个函数,即main函数栈桢的栈底,然后将rsp的值赋给rbp,抬高栈桢底部。
接着从edi中取得参数,并放入位于自身栈桢空间中,rbp之后的双字单元内。
然后执行操作,将其自增。
执行完成之后,将返回值保存在eax中,等待返回。
弹出上一个函数的栈桢的底部,重新回到main函数的空间。
PS:
直到目前为止,这个程序反编译出来的结果和书上说的原理还是有一些出入的,还有下面几个问题:
0x01 书上说的是,传递参数,会将参数按照一定顺序压栈,而不是像本程序中这样使用edi
0x02 在main函数调用funcA函数之后,将栈顶指针esp抬高了,但是在funcA函数执行完成需要返回到main函数的时候,只恢复了ebp指针,并没有恢复esp指针,这是为什么?
希望接下来可以搞懂上面的两个问题。
本文中用到的相关代码和程序下载:
环境:
Windows 10
Python 2.7.10
0x01 安装PyQt4
在这个页面下载,注意选对版本。
https://riverbankcomputing.com/software/pyqt/download
我选择的版本是 PyQt4-4.11.4-gpl-Py2.7-Qt4.8.7-x64.exe
0x02 编写测试脚本
1 | import sys |
如果成功运行并弹出一个空白的窗口,说明PyQt4已经安装上了。
0x03 使用PyQt4的QtWebKit实现解析Dom
待续。
Update your browser to view this website correctly. Update my browser now