环境:
Windows 10
Python 2.7.10
0x01 安装PyQt4
在这个页面下载,注意选对版本。
https://riverbankcomputing.com/software/pyqt/download
我选择的版本是 PyQt4-4.11.4-gpl-Py2.7-Qt4.8.7-x64.exe
0x02 编写测试脚本
1 | import sys |
如果成功运行并弹出一个空白的窗口,说明PyQt4已经安装上了。
0x03 使用PyQt4的QtWebKit实现解析Dom
待续。
环境:
Windows 10
Python 2.7.10
0x01 安装PyQt4
在这个页面下载,注意选对版本。
https://riverbankcomputing.com/software/pyqt/download
我选择的版本是 PyQt4-4.11.4-gpl-Py2.7-Qt4.8.7-x64.exe
0x02 编写测试脚本
1 | import sys |
如果成功运行并弹出一个空白的窗口,说明PyQt4已经安装上了。
0x03 使用PyQt4的QtWebKit实现解析Dom
待续。
1 | array = (1..10).to_a |
1 | length = array.length |
1 | length = array.length-1 |
1 | for i in array do |
1 | array.each{x print x," "} |
1 | length = array.length |
1 | length = array.length |
1 | array.each_index do i |
1 | require 'mysql' |
1 | #!/bin/ruby |
1 | require 'sqlite3' |
服务端:
1 | require 'socket' |
客户端:
1 | require 'socket' |
rubygems.org上的gem文档访问起来太慢了,其实gem本身就自带doc的功能
安装gem的时候会默认安装相应gem的doc,如果不想占用空间安装doc,则gem install XXX –no-doc 即可。
使用下列命令可以启动gem自带的文档:
1 | gem server --port 1234 |
然后访问 http://localhost:1234 就可以查看相关的gem文档。
1 | puts "\033[1m前景色\033[0m\n" |

Ruby json gem
https://rubygems.global.ssl.fastly.net/gems/json-1.8.3.gem
树莓派wiringpi gpio包
http://pi.gadgetoid.com/article/wiringpi-as-a-ruby-gem
参考自:http://rvm.io/rvm/install
首先添加gpg公钥:
1 | gpg --keyserver hkp://keys.gnupg.net --recv-keys 409B6B1796C275462A1703113804BB82D39DC0E3 |
安装稳定版本的rvm
1 | curl -sSL https://get.rvm.io | bash -s stable --ruby |
1 | ruby-2.3.3 - #compiling.......................................................................- |
查看/usr/local/rvm/log/1488041042_ruby-2.3.3/make.log发现是openssl版本过老导致的。
1 | rvm pkg install openssl |
第二步:编译安装ruby,指定openssl目录(我的是/usr/local/rvm/usr/)
1 | rvm install ruby-2.3.3 --with-openssl-dir=/usr/local/rvm/usr/ |
现在没有淘宝源了,只有ruby-china源
1 | gem sources --add https://gems.ruby-china.org/ --remove https://rubygems.org/ |
设置Bundler默认源为ruby-china:
1 | bundle config mirror.https://rubygems.org https://gems.ruby-china.org |
这样修改以后,即使Gemfile中指定了Source,也会用国内的源。
SP_Flash_Tool-v3.1224.0.100
MT6516,MT6573,MT6573,MT6575,MT6575,MT6577
SP_Flash_Tool-v3.1332.0.187
MT6516,MT6573,MT6573,MT6575,MT6575,MT6577,MT6589,MT6572,MT6582,MT8135
SP_Flash_Tool-v3.1344.0.212
MT6516,MT6573,MT6573,MT6575,MT6575,MT6577,MT6589,MT6572,MT6582,MT8135,MT6592,MT6571
SP_Flash_Tool-v5.1352.01
MT6573,MT6573,MT6575,MT6575,MT6577,MT6589,MT6572,MT6571,MT6582,MT8135,MT6592
SP-Flash-Tool-v5.1436.00
MT6573,MT6573,MT6575,MT6575,MT6577,MT6589,MT6572,MT6571,MT6582,MT8135,MT8127,MT6592,MT6595,MT6752
SP-Flash-Tool-v5.1528.00
MT6573,MT6573,MT6575,MT6575,MT6577,MT6589,MT6572,MT6571,MT6582,MT8135,MT8127,MT6592,MT6595,MT6752,
MT2601,MT6795,MT8173,MT6735,MT6735M,MT6753,MT8163,MT8590,MT6580,MT6570
SP-Flash-Tool-v5.1532.00
MT6573,MT6573,MT6575,MT6575,MT6577,MT6589,MT6572,MT6571,MT6582,MT8135,MT8127,MT6592,MT6595,MT6752,
MT2601,MT6795,MT8173,MT6735,MT6735M,MT6753,MT8163,MT8590,MT6580,MT6570,MT6755
SP_Flash_Tool_5.1343
MT6573,MT6573,MT6575,MT6575,MT6577,MT6589,MT6572,MT6571,MT6582,MT8135,MT6592
SP_Flash_Tool_5.1504
MT6573,MT6573,MT6575,MT6575,MT6577,MT6589,MT6572,MT6571,MT6582,MT8135,MT8127,MT6592,MT6595,MT6752,
MT2601,MT6795,MT8173,MT6735,MT6735M,MT6753
SP_Flash_Tool_5.1520
MT6573,MT6573,MT6575,MT6575,MT6577,MT6589,MT6572,MT6571,MT6582,MT8135,MT8127,MT6592,MT6595,MT6752,
MT2601,MT6795,MT8173,MT6735,MT6735M,MT6753,MT8163,MT8590,MT6580,MT6570
SP_Flash_Tool_5.1524.00
MT6573,MT6573,MT6575,MT6575,MT6577,MT6589,MT6572,MT6571,MT6582,MT8135,MT8127,MT6592,MT6595,MT6752,
MT2601,MT6795,MT8173,MT6735,MT6735M,MT6753,MT8163,MT8590,MT6580,MT6570
SP_Flash_Tool_v5.1452
MT6573,MT6573,MT6575,MT6575,MT6577,MT6589,MT6572,MT6571,MT6582,MT8135,MT8127,MT6592,MT6595,MT6752,
MT2601,MT6795,MT8173,MT6735,MT6735M,MT6753
SP_Flash_Tool_v5.1512
MT6573,MT6573,MT6575,MT6575,MT6577,MT6589,MT6572,MT6571,MT6582,MT8135,MT8127,MT6592,MT6595,MT6752,
MT2601,MT6795,MT8173,MT6735,MT6735M,MT6753,MT8163,MT8590,MT6580,MT6570
SP_Flash_Tool_v5.1516
MT6573,MT6573,MT6575,MT6575,MT6577,MT6589,MT6572,MT6571,MT6582,MT8135,MT8127,MT6592,MT6595,MT6752,
MT2601,MT6795,MT8173,MT6735,MT6735M,MT6753,MT8163,MT8590,MT6580,MT6570
SP_Flash_Tool_v5.1548
MT6573,MT6573,MT6575,MT6575,MT6577,MT6589,MT6572,MT6571,MT6582,MT8135,MT8127,MT6592,MT6595,MT6752,
MT2601,MT6795,MT8173,MT6735,MT6737,MT6735M,MT6753,MT8163,MT8590,MT6580,MT6570,MT6755,MT6797
SP_Flash_Tool_v5.1552
MT6573,MT6573,MT6575,MT6575,MT6577,MT6589,MT6572,MT6571,MT6582,MT8135,MT8127,MT6592,MT6595,MT6752,
MT2601,MT6795,MT8173,MT6735,MT6737T,MT6735M,MT6737M,MT6753,MT8163,MT8590,MT7623,MT6580,MT6570,
MT6755,MT6797
SP_Flash_Tool_v5.1604
MT6573,MT6573,MT6575,MT6575,MT6577,MT6589,MT6572,MT6571,MT6582,MT8135,MT8127,MT6592,MT6595,MT6752,
MT2601,MT6795,MT8173,MT6735,MT6737T,MT6735M,MT6737M,MT6753,MT8163,MT8590,MT7623,MT6580,MT6570,
MT6755,MT6750,MT6797
SP_Flash_Tool_v5.1612
MT6573,MT6573,MT6575,MT6575,MT6577,MT6589,MT6572,MT6571,MT6582,MT8135,MT8127,MT6592,MT6595,MT6752,
MT2601,MT6795,MT8173,MT6735,MT6737T,MT6735M,MT6737M,MT6753,MT8163,MT8590,MT7623,MT6580,MT6570,
MT6755,MT6750,MT6797,MT6757
SP_Flash_Tool_v5.1616_Win
MT6573,MT6573,MT6575,MT6575,MT6577,MT6589,MT6572,MT6571,MT6582,MT8135,MT8127,MT6592,MT6595,MT6752,
MT2601,MT6795,MT8173,MT6735,MT6737T,MT6735M,MT6737M,MT6753,MT8163,MT8590,MT7623,MT6580,MT6570,
MT6755,MT6750,MT6797,MT6757,ELBRUS,MT6798,MT0507
SP_Flash_Tool_v5.1620_Win
MT6573,MT6573,MT6575,MT6575,MT6577,MT6589,MT6572,MT6571,MT6582,MT8135,MT8127,MT6592,MT6595,MT6752,
MT2601,MT6795,MT8173,MT6735,MT6737T,MT6735M,MT6737M,MT6753,MT8163,MT8590,MT7623,MT6580,MT6570,
MT6755,MT6750,MT6797,MT6757,ELBRUS,MT6798,MT0507,MT8160,MT0633
SP_Flash_Tool_v5.1624_Win
MT6573,MT6573,MT6575,MT6575,MT6577,MT6589,MT6572,MT6571,MT6582,MT8135,MT8127,MT6592,MT6595,MT6752,
MT2601,MT6795,MT8173,MT6735,MT6737T,MT6735M,MT6737M,MT6753,MT8163,MT8590,MT7623,MT6580,MT6570,
MT6755,MT6750,MT6797,MT6757,ELBRUS,MT6798,MT0507,MT8167,MT0633
SP_Flash_Tool_v5.1628_Win
MT6573,MT6573,MT6575,MT6575,MT6577,MT6589,MT6572,MT6571,MT6582,MT8135,MT8127,MT6592,MT6595,MT6752,
MT2601,MT6795,MT8173,MT6735,MT6737T,MT6735M,MT6737M,MT6753,MT8163,MT8590,MT7623,MT6580,MT6570,
MT6755,MT6750,MT6797,MT6757,ELBRUS,MT6799,MT0507,MT8167,MT0633
SP_Flash_Tool_v5.1632_Win
MT6573,MT6573,MT6575,MT6575,MT6577,MT6589,MT6572,MT6571,MT6582,MT8135,MT8127,MT6592,MT6595,MT6752,
MT2601,MT6795,MT8173,MT6735,MT6737T,MT6735M,MT6737M,MT6753,MT8163,MT8590,MT8521,MT7623,MT6580,
MT6570,MT6755,MT6750,MT6797,MT6757,ELBRUS,MT6799,MT0507,MT8167,MT6570,MT0690
SP_Flash_Tool_v5.1636_Win
MT6573,MT6573,MT6575,MT6575,MT6577,MT6589,MT6572,MT6571,MT6582,MT8135,MT8127,MT6592,MT6595,MT6752,
MT2601,MT6795,MT8173,MT6735,MT6737T,MT6735M,MT6737M,MT6753,MT8163,MT8590,MT8521,MT7623,MT6580,
MT6570,MT6755,MT6750,MT6797,MT6757,ELBRUS,MT6799,MT6798,MT8167,MT6570,MT0690
SP_Flash_Tool_v5.1640_Win
MT6573,MT6573,MT6575,MT6575,MT6577,MT6589,MT6572,MT6571,MT6582,MT8135,MT8127,MT6592,MT6595,MT6752,
MT2601,MT6795,MT8173,MT6735,MT6737T,MT6735M,MT6737M,MT6753,MT8163,MT8590,MT8521,MT7623,MT6580,
MT6570,MT6755,MT6750,MT6797,MT6757,MT6757D,ELBRUS,MT6799,MT6798,MT8167,MT6570,MT0690
SP_Flash_Tool_v5.1644_Win
MT6573,MT6573,MT6575,MT6575,MT6577,MT6589,MT6572,MT6571,MT6582,MT8135,MT8127,MT6592,MT6595,MT6752,
MT2601,MT6795,MT8173,MT6735,MT6737T,MT6735M,MT6737M,MT6753,MT8163,MT8590,MT8521,MT7623,MT6580,
MT6570,MT6755,MT6750,MT6797,MT6757,MT6757D,ELBRUS,MT6799,MT6798,MT8167,MT6570,MT0690
SP_Flash_Tool_v5.1648_Win
MT6573,MT6573,MT6575,MT6575,MT6577,MT6589,MT6572,MT6571,MT6582,MT8135,MT8127,MT6592,MT6595,MT6752,
MT2601,MT6795,MT8173,MT6735,MT6737T,MT6735M,MT6737M,MT6753,MT8163,MT8590,MT8521,MT7623,MT6580,
MT6570,MT6755,MT6750,MT6797,MT6757,MT6757D,ELBRUS,MT6799,MT6759,MT8167,MT8516,MT6570,MT6763
VC
1 | #include <stdio.h> |
GCC
1 | #include <stdio.h> |

VmWare默认的镜像格式是.vmdk格式的,VirtualBox则默认是.vdi格式的。其实这在VirtualBox新建虚拟机的过程中是可选的。
导入.vmdk格式的镜像到VirtualBox只需要新建一个虚拟机,并且不创建虚拟硬盘。如下图:
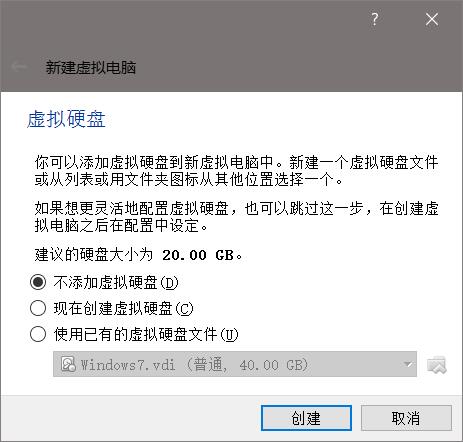
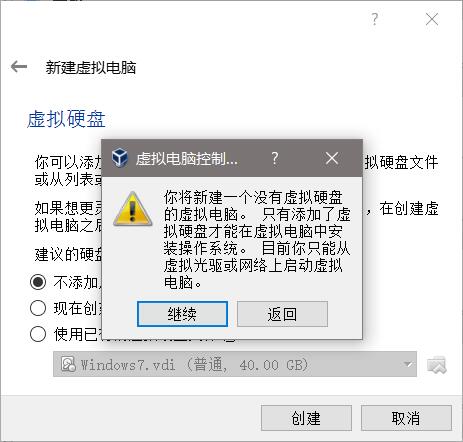
无视警告,继续:
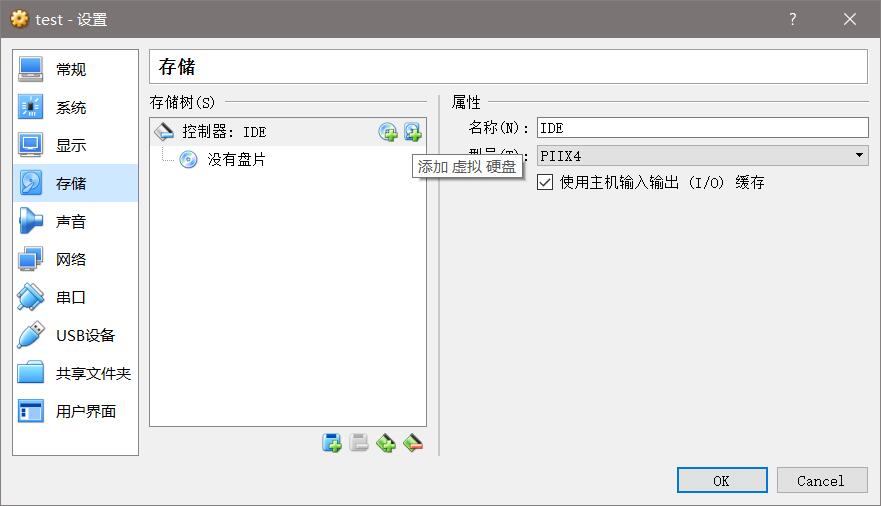
创建好之后,在设置里面把.vmdk格式的虚拟硬盘添加进去:
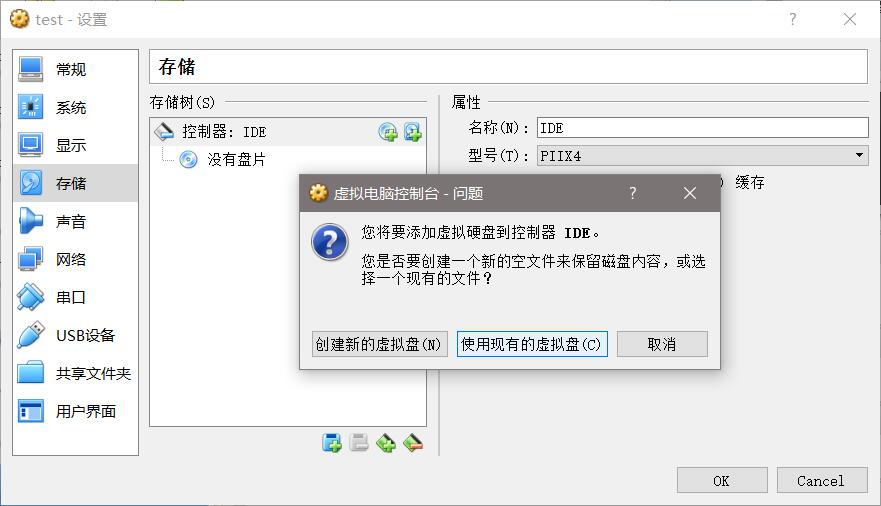
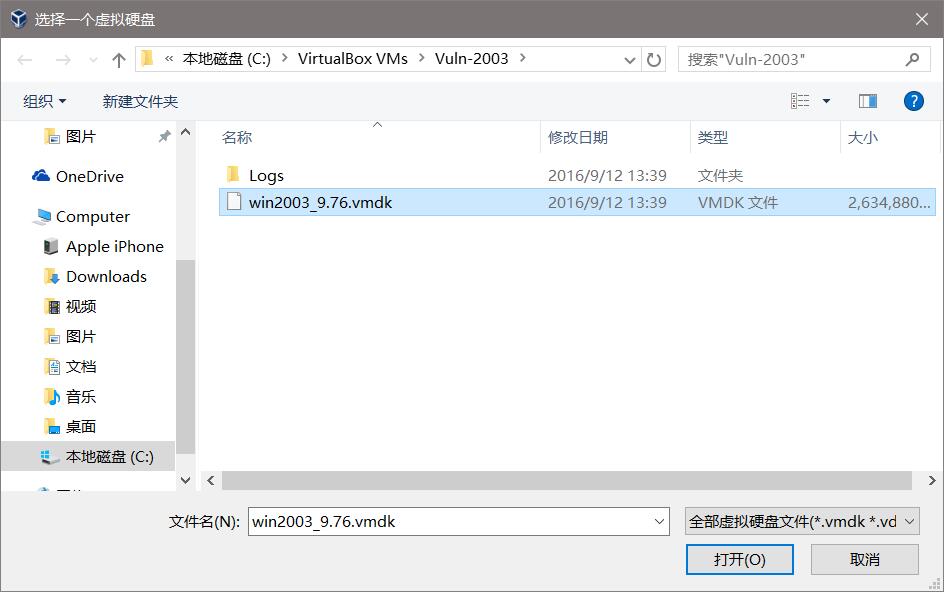
这样就可以了。
如果遇到windows虚拟机起不开的情况,尝试更改下下面这个选项,启用I/O APIC试试。
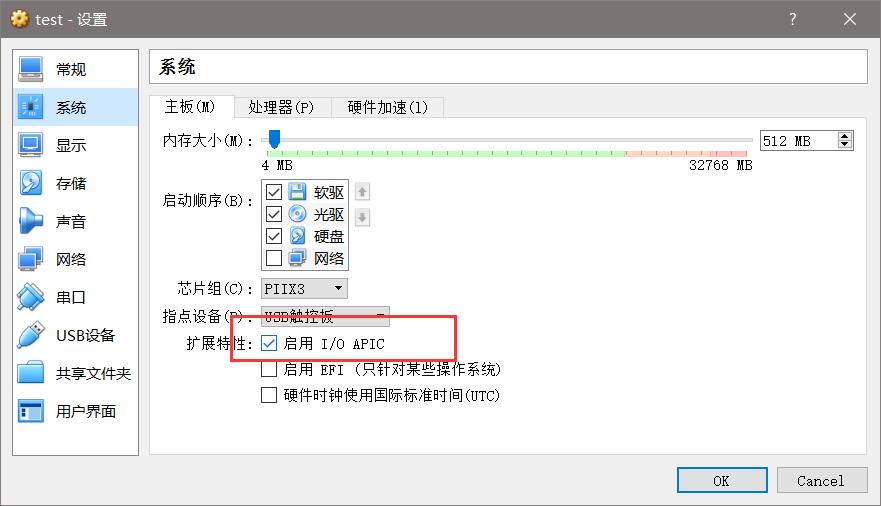
1 | set JAVA_HOME=C:\Program Files\Java\jdk1.8.0_40 |
建立热点:
@echo off
netsh wlan set hostednetwork mode=allow
netsh wlan set hostednetwork ssid=热点名 key=密码
netsh wlan start hostednetwork
关闭热点
netsh wlan set hostednetwork mode=disallow
创建项目
1 | rails new BootstrapProject |
创建模型
1 | rails g scaffold xxx --skip-stylesheets |
运行迁移
1 | rake db:migrate |
如果项目和模型都已经建立好了并已经运行了迁移,那么可以省略以上步骤,直接进入下面的流程
在Gemfile中添加bootstrap,这里使用twitter-bootstrap-rails
1 | gem 'jquery-rails' |
bundle
1 | bundle install |
安装bootstrap
1 | rails g bootstrap:install |
在模型上运用bootstrap
1 | rails g bootstrap:themed xxx -f |
注:xxx可以是任意的模型,例如模型名称是Article,那么这里的语句就是:
1 | rails g bootstrap:themed Articles |
还要在application.js中加上引用,否则bootstrap的一些按钮会失效:
1 | //= require jquery |
Enjoy it~
最近手上多了一个树莓派2代,于是折腾就这么开始了。
因为总是得要个显示屏或者路由器或者插根网线才能玩,有点麻烦,所以有了此文。
设备清单:
树莓派2代
EDUP EP-N8508GS无线网卡(USB)
普通网线一根
最终实现的效果是树莓派的有线网卡用来作为wan口,无线网卡建立热点
笔记本可以通过连接wifi连接上树莓派进行操作
下面说说过程:
首先我参考了
http://elinux.org/RPI-Wireless-Hotspot
这篇文章中的方法,但是并没有成功。后来看到文章的末尾才知道,是驱动对不上号,文章末尾明确标明默认的hostapd程序不支持rtl8188系列网卡,而我的usb网卡就是rtl8188cus系列。
所以在开始之前,建议先用lsusb命令看一下网卡的型号再考虑进行下一步。
如果你的网卡不是rtl8188系列那你可以参考上面文章中的方法来配置,如果是那么可以参考我的方法。
根据那篇文章最后给出的连接,找到了这个驱动:
https://github.com/lostincynicism/hostapd-rtl8188
然而当编译好驱动重新运行之后仍然是不行,还是不支持。
最后还是参考了这篇文章:
http://wangye.org/blog/archives/845/?_t_t_t=0.7382462719884554
原因可能就是因为我这个系列网卡比较特殊。但是最后在这个文章中发现了编译好的第三方驱动,虽然有点不满意,但还是凑合着用了。
http://www.daveconroy.com/turn-your-raspberry-pi-into-a-wifi-hotspot-with-edimax-nano-usb-ew-7811un-rtl8188cus-chipset/
具体步骤:
先切换为root用户,可以省去很多不必要的麻烦。
所以以下操作都是以root用户:
1.安装hostapd和udhcpd服务并且更换hostapd程序
apt-get install udhcpd hostapd
wget http://www.daveconroy.com/wp3/wp-content/uploads/2013/07/hostapd.zip
unzip hostapd.zip
mv /usr/sbin/hostapd /usr/sbin/hostapd.bak
mv hostapd /usr/sbin/hostapd.edimax
ln -sf /usr/sbin/hostapd.edimax /usr/sbin/hostapd
chown root.root /usr/sbin/hostapd
chmod 755 /usr/sbin/hostapd
2.编辑/etc/udhcpd.conf文件,配置dhcp服务:
确保文件当中有下列内容
start 192.168.1.2
end 192.168.1.254
interface wlan0
remaining yes
opt dns 223.5.5.5 223.6.6.6
opt subnet 255.255.255.0
opt router 192.168.1.1
opt lease 864000 #
相信一般都能看懂,其中的interface需要根据情况来写。
3.编辑/etc/default/udhcpd 文件,将下面这行注释掉。
DHCPD_ENABLED="no"
4.将无线网卡wlan0的ip设为192.168.1.1
ifconfig wlan0 192.168.42.1
5.修改/etc/network/interfaces文件,添加下面的内容
iface wlan0 inet static
address 192.168.1.1
netmask 255.255.255.0
并且将下面这两条注释掉
wpa-roam /etc/wpa_supplicant/wpa_supplicant.conf
iface default inet manual
6.接着就正式开始配置无线相关的选项了,编辑/etc/hostapd/hostapd.conf,如果没有这个文件就自行创建它。
interface=wlan0
driver=rtl871xdrv
ssid=无线名称
hw_mode=g
channel=6
macaddr_acl=0
auth_algs=1
ignore_broadcast_ssid=0
wpa=2
wpa_passphrase=无线密码
wpa_key_mgmt=WPA-PSK
wpa_pairwise=TKIP
rsn_pairwise=CCMP
7.在/etc/default/hostapd文件中指定hostapd服务的配置文件,内容如下
DAEMON_CONF="/etc/hostapd/hostapd.conf"
8.更改系统的转发规则和iptables规则,依次运行下列命令:
echo 1 > /proc/sys/net/ipv4/ip_forward
iptables -t nat -A POSTROUTING -o eth0 -j MASQUERADE
iptables -A FORWARD -i eth0 -o wlan0 -m state --state RELATED,ESTABLISHED -j ACCEPT
iptables -A FORWARD -i wlan0 -o eth0 -j ACCEPT
iptables-save > /etc/iptables.nat
service hostapd start
service udhcpd start
update-rc.d hostapd enable
update-rc.d udhcpd enable
9.最后一点点收尾工作:
编辑/etc/network/interfaces文件,在末尾加上着一条:
up iptables-restore < /etc/iptables.nat
以及/etc/sysctl.conf文件,确保下面的选项存在
net.ipv4.ip_forward=1
到此为止就全部完成了,用手机,电脑等无线设备都可以连接上树莓派了。
为后续的折腾打下基础。
折腾的整个过程还挺复杂的,需要修改多处文件,而且每一处修改都会微妙的影响到最后路由器的运行,小小的改变都有可能造成瘫痪或者影响性能。由此可见,想DIY一款高性能的个性无线路由器还是很有挑战性的。
1、Linux 基础
安装Linux操作系统
Linux文件系统
Linux常用命令
Linux启动过程详解
熟悉Linux服务能够独立安装Linux操作系统
能够熟练使用Linux系统的基本命令
认识Linux系统的常用服务安装Linux操作系统
Linux基本命令实践
设置Linux环境变量
定制Linux的服务
Shell 编程基础使用vi编辑文件
使用Emacs编辑文件使用其他编辑器
2
认识后台程序Bash编程熟悉Linux系统下的编辑环境熟悉Linux下的各种Shell 熟练进行shell编程熟悉vi基本操作 熟悉Emacs的基本操作比较不同shell的区别 编写一个测试服务器是否连通的shell脚本程序编写一个查看进程是否存在的shell脚本程序 编写一个带有循环语句的shell脚本程序
3、Linux 下的 C 编程基础
linux C语言环境概述 Gcc使用方法 Gdb调试技术 Autoconf Automake Makefile 代码优化 熟悉Linux系统下的开发环境熟悉Gcc编译器 熟悉Makefile规则编写Hello,
chi dazzle,World程序 使用 make命令编译程序 编写带有一个循环的程序调试一个有问题的程序
4、嵌入式系统开发基础
嵌入式系统概述 交叉编译 配置TFTP服务 配置NFS服务下载Bootloader和内核 嵌入式Linux应用软件开发流程熟悉嵌入式系统概念以及开发流程建立嵌入式系统开发环境制作cross_gcc工具链 编译并下载U-boot 编译并下载Linux内核 编译并下载Linux应用程序
4、嵌入式系统移植
Linux内核代码 平台相关代码分析 ARM平台介绍 平台移植的关键技术 移植Linux内核到 ARM平台 了解移植的概念 能够移植Linux内核移植Linux2.6内核到 ARM9开发板
5、嵌入式 Linux 下串口通信
串行I/O的基本概念 嵌入式Linux应用软件开发流程 Linux系统的文件和设备 与文件相关的系统调用 配置超级终端和MiniCOM能够熟悉进行串口通信熟悉文件I/O 编写串口通信程序 编写多串口通信程序
6、嵌入式系统中多进程程序设计
Linux系统进程概述 嵌入式系统的进程特点 进程操作 守护进程 相关的系统调用了解Linux系统中进程的概念能够编写多进程程序编写多进程程序 编写一个守护进程程序 sleep系统调用任务管理、同步与通信 Linux任务概述任务调度 管道 信号 共享内存 任务管理 API 了解Linux系统任务管理机制 熟悉进程间通信的几种方式 熟悉嵌入式Linux中的任务间同步与通信编写一个简单的管道程序实现文件传输编写一个使用共享内存的程序
7、嵌入式系统中多线程程序设计
线程的基础知识 多线程编程方法 线程应用中的同步问题了解线程的概念 能够编写简单的多线程程序编写一个多线程程序
8、嵌入式 Linux 网络编程
网络基础知识 嵌入式Linux中TCP/IP网络结构 socket 编程 常用 API函数 分析Ping命令的实现 基本UDP套接口编程 许可证管理PPP协议 GPRS 了解嵌入式Linux网络体系结构能够进行嵌入式Linux环境下的socket 编程 熟悉UDP协议、PPP协议 熟悉GPRS 使用socket 编写代理服务器 使用socket 编写路由器 编写许可证服务器指出TCP和UDP的优缺点 编写一个web服务器 编写一个运行在 ARM平台的网络播放器
9、GUI 程序开发
GUI基础 嵌入式系统GUI类型 编译QT 进行QT开发熟悉嵌入式系统常用的GUI 能够进行QT编程使用QT编写“Hello,World”程序 调试一个加入信号/槽的实例 通过重载QWidget 类方法处理事件
10、Linux 字符设备驱动程序
设备驱动程序基础知识 Linux系统的模块 字符设备驱动分析 fs_operation结构 加载驱动程序了解设备驱动程序的概念 了解Linux字符设备驱动程序结构能够编写字符设备驱动程序编写Skull驱动 编写键盘驱动 编写I/O驱动分析一个看门狗驱动程序 对比Linux2.6内核与2.4内核中字符设备驱动的不同Linux 块设备驱动程序块设备驱动程序工作原理 典型的块设备驱动程序分析 块设备的读写请求队列了解Linux块设备驱动程序结构 能够编写简单的块设备驱动程序比较字符设备与块设备的异同 编写MMC卡驱动程序 分析一个文件系统 对比Linux2.6内核与2.4内核中块设备驱动的不同
11、文件系统
虚拟文件系统 文件系统的建立 ramfs内存文件系统 proc文件系统 devfs 文件系统 MTD技术简介 MTD块设备初始化 MTD块设备的读写操作了解Linux系统的文件系统了解嵌入式Linux的文件系统 了解MTD技术 能够编写简单的文件系统为 ARM9开发板添加 MTD支持 移植JFFS2文件系统通过proc文件系统修改操作系统参数 分析romfs 文件系统源代码创建一个cramfs 文件系统 、Shell 编程基础
Shell简介
<二>
学习掌握嵌入 Linux 的开发与移植 现在非常流行。
各种学习文章与培训班,充斥书店 街头。
笔者 也上了路,经历漫长的摸索,终于一日开窍,但的确 糟蹋了 很多 金钱与时间。 作为穷人,现写下自己的感受,供好学寒士 参考。
第一要点: 实验重于看书 (多编码,少翻书)
一定首先搭建x86实验环境。
用旧计算机(周末电脑城抛售存货,有新的),搭建一套 实验环境。
host主机: 一台PC机(能够跑redhat linux,看问档 就可以了,配网卡与软驱)。
target目标机: 一块旧PC主板,配一张网卡和一个软驱,电源。
附件: 交网线 ,交串口线
够了,不会超过3千元(已经很满足了)。
软件全部到 电脑城/网站 下载。
先不管什么arm ppc mips, 以后看看文档吧。
第二重点:GNU C编译
在PC 上安装 redhat linux 包括 开发工具。
熟悉linux 的配置命令。
练习 linux 的 C 语言编程,多个程序的编译工程制作。
无聊的话,将C语言教材的例程,编译十几个,熟悉GNU 编译器。www.gnu.org
包括gcc make ld objdump ar 等 GNU toolkit
第三重点:realtime linux 内核编程/加载到目标板运行。
1。 下载 rt-linux ,或uclinux 或什么 非 redhat的linux 源码,一定 是包括,编译工程makefile, 并且for x86 PC的。
2。修改和配置程序,将 rtlinux的 标准 console口 改为串口,不是vga与键盘。
3。在redhat linux 环境下,编译 这个 embedded linux内核。
用mkboot的这样程序(或按代码中工具,) 将编译好的内核执行文件 拷贝定位软盘引导区。
4。用这张软盘引导在目标PC主板 。
在PC主机的 串口终端上配置 PC主板目标机。 效果同 redhat linux terminal console一样。
以后越来月难,坚持。
第四个重点 编译跑通网卡的驱动程序
下载编译 你的网卡驱动源码
跑通 主机与目标机的 网络通讯。
不要太动头想, ping 通就是了。
第五个重点 用tftp 下载执行文件从 PC主机 到 目标机运行。
第六个重点 GNU GDB 远程在线调试(网口调试)
第七个重点 实时内核学习/修改
照文章/书 分析调试/破坏 内核的源码。
主要是 调度/消息/存储/文件/进程/线程/互斥 等
单独跑跑, 了解内核功能就是了。
第八个重点 TCP/IP的学习
下载一个 简单的web server (http server)
学习理解,并编译加载运行。
将 PC主板目标机 看作网站服务器,然后在PC主机的网络浏难器中 访问这个 web server.
有兴趣,把你的照片加载到目标机的 html网页中。
www.zebra.org
第九个重点 网卡驱动程序分析
了解 PCI总线原理,尝试独立写点网卡驱动程序,过滤以太报文的处理。 跟踪处理 特殊的报文。
第十个重点USB和 FLASH文件系统练习。(可以跳过)
可以分析修改 USB与FLASH文件系统源码。
一定要分析源码,上网查 FLASH的型号。
第十一个重点 路由器实验。
分析zebra方面的源码,再买一张网卡。
尝试分析 NAT RIP等协议,将你的PC板目标机,变成一台简单的路由器。
以后的实验 需要根据 行业来,
例如,mini-GUI (图形编程),或 DVR (硬盘录象机),或IP Vedio WebTV 服务器。
可以玩好几年,当然最好找工作前,有针对地做实验。
一句话,动手修改编码,不要只看看。
<三>
嵌入式Linux操作系统学习规划
ARM+LINUX路线,主攻嵌入式Linux操作系统及其上应用软件开发目标:
(1) 掌握主流嵌入式微处理器的结构与原理(初步定为arm9)
(2) 必须掌握一个嵌入式操作系统 (初步定为uclinux或linux,版本待定)
(3) 必须熟悉嵌入式软件开发流程并至少做一个嵌入式软件项目。
从事嵌入式软件开发的好处是:
(1)目前国内外这方面的人都很稀缺。这一领域入门门槛较高,所以非专业IT人员很难切入这一领域;另一方面,是因为这一领域较新,目前发展太快,大多数人无条件接触。
(2)与企业计算等应用软件不同,嵌入式领域人才的工作强度通常低一些(但收入不低)。
(3)哪天若想创业,搞自已的产品,嵌入式不像应用软件那样容易被盗版。硬件设计一般都是请其它公司给订做(这叫“贴牌”:OEM),都是通用的硬件,我们只管设计软件就变成自己的产品了。
(4)兴趣所在,这是最主要的。
从事嵌入式软件开发的缺点是:
(1)入门起点较高,所用到的技术往往都有一定难度,若软硬件基础不好,特别是操作系统级软件功底不深,则可能不适于此行。
(2)这方面的企业数量要远少于企业计算类企业。
(3)有少数公司经常要硕士以上的人搞嵌入式,主要是基于嵌入式的难度。但大多数公司也并无此要求,只要有经验即可。
(4)平台依托强,换平台比较辛苦。
兴趣的由来:
1、成功观念不同,不虚度此生,就是我的成功。
2、喜欢思考,挑战逻辑思维。
3、喜欢C
C是一种能发挥思维极限的语言。关于C的精神的一些方面可以被概述成短句如下:
相信程序员。
不要阻止程序员做那些需要去做的。
保持语言短小精干。
一种方法做一个操作。
使得它运行的够快,尽管它并不能保证将是可移植的。
4、喜欢底层开发,讨厌vb类开发工具(并不是说vb不好)。
5、发展前景好,适合创业,不想自己要死了的时候还是一个工程师。
方法步骤:
1、基础知识:
目的:能看懂硬件工作原理,但重点在嵌入式软件,特别是操作系统级软件,那将是我的优势。
科目:数字电路、计算机组成原理、嵌入式微处理器结构。
汇编语言、C/C++、编译原理、离散数学。
数据结构和算法、操作系统、软件工程、网络、数据库。
方法:虽科目众多,但都是较简单的基础,且大部分已掌握。不一定全学,可根据需要选修。
主攻书籍:the c++ programming language(一直没时间读)、数据结构-C2。
2、学习linux:
目的:深入掌握linux系统。
方法:使用linux—〉linxu系统编程开发—〉驱动开发和分析linux内核。先看深,那主讲原理。看几遍后,看情景分析,对照深看,两本交叉,深是纲,情是目。剖析则是0.11版,适合学习。最后深入代码。
主攻书籍:linux内核完全剖析、unix环境高级编程、深入理解linux内核、情景分析和源代。
3、学习嵌入式linux:
目的:掌握嵌入式处理器其及系统。
方法:(1)嵌入式微处理器结构与应用:直接arm原理及汇编即可,不要重复x86。
(2)嵌入式操作系统类:ucOS/II简单,开源,可供入门。而后深入研究uClinux。
(3)必须有块开发板(arm9以上),有条件可参加培训(进步快,能认识些朋友)。
主攻书籍:毛德操的《嵌入式系统》及其他arm9手册与arm汇编指令等。
4、深入学习:
A、数字图像压缩技术:主要是应掌握MPEG、mp3等编解码算法和技术。
B、通信协议及编程技术:TCP/IP协议、802.11,Bluetooth,GPRS、GSM、CDMA等。
C、网络与信息安全技术:如加密技术,数字证书CA等。
D、DSP技术:Digital Signal Process,DSP处理器通过硬件实现数字信号处理算法。
说明:太多细节未说明,可根据实际情况调整。重点在于1、3,不必完全按照顺序作。对于学习c++,理由是c++不只是一种语言,一种工具,她还是一种艺术,一种文化,一种哲学理念、但不是拿来炫耀得东西。对于linux内核,学习编程,读一些优秀代码也是有必要的。
注意: 要学会举一反多,有强大的基础,很多东西简单看看就能会。想成为合格的程序员,前提是必须熟练至少一种编程语言,并具有良好的逻辑思维。一定要理论结合实践。
不要一味钻研技术,虽然挤出时间是很难做到的,但还是要留点余地去完善其他的爱好,比如宇宙,素描、机械、管理,心理学、游戏、科幻电影。还有一些不愿意做但必须要做的!
技术是通过编程编程在编程编出来的。永远不要梦想一步登天,不要做浮躁的人,不要觉得路途漫上。而是要编程编程在编程,完了在编程,在编程!等机会来了在创业(不要相信有奇迹发生,盲目创业很难成功,即便成功了发展空间也不一定很大)。
嵌入式书籍推荐
Linux基础
1、《Linux与Unix Shell 编程指南》
C语言基础
1、《C Primer Plus,5th Edition》【美】Stephen Prata着
2、《The C Programming Language, 2nd Edition》【美】Brian W. Kernighan David M. Rithie(K & R)着
3、《Advanced Programming in the UNIX Environment,2nd Edition》(APUE)
4、《嵌入式Linux应用程序开发详解》
Linux内核
1、《深入理解Linux内核》(第三版)
2、《Linux内核源代码情景分析》毛德操 胡希明著
研发方向
1、《UNIX Network Programming》(UNP)
2、《TCP/IP详解》
3、《Linux内核编程》
4、《Linux设备驱动开发》(LDD)
5、《Linux高级程序设计》 杨宗德著
硬件基础
1、《ARM体系结构与编程》杜春雷着
2、S3C2410 Datasheet
英语基础
1、《计算机与通信专业英语》
系统教程
1、《嵌入式系统――体系结构、编程与设计》
2、《嵌入式系统――采用公开源代码和StrongARM/Xscale处理器》毛德操 胡希明着
3、《Building Embedded Linux Systems》
4、《嵌入式ARM系统原理与实例开发》 杨宗德著
理论基础
1、《算法导论》
2、《数据结构(C语言版)》
3、《计算机组织与体系结构?性能分析》
4、《深入理解计算机系统》【美】Randal E. Bryant David O’’Hallaron着
5、《操作系统:精髓与设计原理》
6、《编译原理》
7、《数据通信与计算机网络》
8、《数据压缩原理与应用》
C语言书籍推荐
1. The C programming language 《C程序设计语言》
2. Pointers on C 《C和指针》
3. C traps and pitfalls 《C陷阱与缺陷》
4. Expert C Lanuage 《专家C编程》
5. Writing Clean Code —–Microsoft Techiniques for Developing Bug-free C Programs
《编程精粹–Microsoft 编写优质无错C程序秘诀》
6. Programming Embedded Systems in C and C++ 《嵌入式系统编程》
7.《C语言嵌入式系统编程修炼》
8.《高质量C++/C编程指南》林锐
尽可能多的编码,要学好C,不能只注重C本身。算法,架构方式等都很重要。
这里很多书其实是推荐而已,不必太在意,关键还是基础,才是重中之重!!!
<四>
嵌入式Linux学习的基本的原则是通学+专长。
通学,即了解该方向的相关领域,但是“通”不等于“泛”,对待学习应该举一反三,把握事物的本质。如果能用通用的思想去解决问题,那么才算学有小成。比如,五一学习Mark Balch的《COMPLETE DIGITAL DESIGN》后,对嵌入式系统在上电之后,软硬件如何配合工作有了更深入的理解。虽然这本书不是介绍嵌入式系统,但是很多技术是通用的。有开放的思维,把握自己研究的中心,把其他领域的方法思想吸收过来为我所用,这样可以对研究中心有更为深入的认识。
专长,即研究中心。通学的目的在于打好基础,融会贯通。但是仅仅如此是不够的。因为通学不可能把每个方向都研究精深,人的精力毕竟是有限的嘛,所以要有自己感兴趣的方向,以此作为研究中心,深入深入再深入,成为该方向的专家。以通促专,提炼自己的思想,以开放的思维谋求最大的提升!
我选择的研究领域是嵌入式系统(ARM+Linux),在该领域有四种类型的工作:
1、系统设计
2、硬件设计
3、驱动开发及内核移植
4、应用开发
基于我目前的认识,研究中心是驱动开发及内核移植,争取以后做系统设计,成为嵌入式系统设计工程师。
嵌入式Linux学习分为三个阶段:
第一阶段:建立嵌入式Linux知识体系框架。
第二阶段:深入学习嵌入式Linux的基本技术。
第三阶段:精深专长。
这三个阶段可以交叉。第一阶段通过2006年暑假两个月的强化学习,已经完成。现在正在进行第二阶段的学习。这个阶段关注嵌入式Linux软件开发的基本技术,包括:JTAG的工作原理及其实现(以JFlash为主)、bootloader的原理及实现(以U-boot为主)、kernel移植与开发(尝试2.4.18、2.6.X)、FS制作(尝试ramdisk、cromfs等)、应用程序的移植(基本掌握开发)、调试和诊断技术。在这个阶段,同时打好硬件基础(掌握S3C2410)和软件基础(bash、C和基本的开发工具)。第三个阶段在读研期间,以研究OS原理和Linux内核源代码为主,与第二阶段交叉进行。
其实,每天进步一点点,把这一点点所学加到已经建立的知识体系框架中,日积月累,思想认识必定会有所提升。虽然都认可宁可断其一指,不可伤其十指,但是应该承认人的认识是有局限性的。比如学习A时,因缺乏实践等各方面原因,可能认识不深入,也许在学习B时突然认识到了。所以一定要举一反三,而且要反复学习。记住基础的技术,努力学习先进技术,不停止前进的脚步。
<五>
【序】学习Linux开发近一年,由于我是实验室第一个从事这方面开发的,学习过程中遇到了很多问题,可是总是求师无门,只能一个人自己摸索,同时也充分利用了网络,参考了广大CSDN博友及相关论坛的帖子,在此表示感谢!
嵌入式Linux的学习涵盖的范围比较广,下从bootloader,到内核移植、文件系统,中间的驱动开发,到上层的应用程序调试、开发环境等,变化莫测,经常是别人的能用自己的就有问题。
由于缺乏他人适当指点,自己在学习过程中也走了很多弯路,整个开发环境的搭建整了N久,更搞笑的是经常听说模块加载insmod,可连这个命令在主机还是ARM上用都没搞明白,那叫一个汗啊!大家勿笑,嵌入式Linux的初学者确实对交叉环境比较不懂,我是其一啊。
现在适逢好友小布丁要学习嵌入式Linux,就将近一年来的学习体会总结下,整理了一个总体的学习计划,希望给那些曾经像我一样彷徨的人一些帮助。后续将完善此文档,上传到个人空间上,先贴出目录。本人水平有限,不当之处,还请大家指正!
小布丁同学曾在我处于困境时一如既往的理解我支持我,给我信心给我鼓励,谢谢你,美丽开怀的小布丁,希望你能happy and fascinating forever!
谨以此文献给我们永远可爱迷人的小布丁!
Sailor_forever
September 3, 2007
第一篇 Linux主机开发环境(15天)
1.1 Vmvare下Linux的安装(优先)
1.2 Windows下从硬盘安装Linux(可选)
1.3 Linux的基本命令及使用
1.4 Linux的文件系统及与windows的文件共享
1.5 GCC开发工具
1.6 GDB调试
1.7 Makefile编写
1.8 主机端的模块编程
1.9 简单应用程序
第二篇 ARM+Linux开发环境(7天)
2.1 交叉开发环境介绍
2.2 交叉编译器cross-tool
2.3 配置主机开发环境
2.3.1 配置超级终端minicom或hyperterminal或DNW
2.3.2 配置TFTP网络服务
2.3.3 配置NFS主机端网络服务
2.4 建立交叉开发环境
2.4.1配置NFS ARM端网络服务
2.4.2 编译ARM-gdb
2.5 交叉调试应用程序
2.6 ARM上的简单模块编程
第三篇 Linux系统bootlaoder移植(7天)
3.1 Bootloader介绍
3.2 u-boot命令及环境变量
3.3 u-boot的编译配置
3.4 u-boot源码分析
3.5 u-boot移植过程
第四篇 Linux的内核移植(15天)
4.1 配置编译Linux内核
4.1.1 Linux内核源代码结构
4.1.2 Linux内核编译选项解析
4.1.3 Linux内核编译链接
4.2 Linux启动过程源代码分析
4.3 Linux内核移植平台相关代码分析
第五篇 Linux的驱动编程(15天)
5.1 Linux的设备管理
5.2 Linux的驱动程序结构
5.3 简单的字符设备驱动程序
5.4 Linux内核模块的加载卸载
5.5 Linux的打印调试方法
5.6 字符设备的高级属性-中断
5.6 常见的串口网口驱动分析
第六篇 文件系统制作(5天)
6.1 Linux文件系统制作
6.2 文件系统和存储设备的选择
6.3 部署Ramdisk文件系统的过程
第七篇 Linux的高级应用编程(5天)
总用时 15+7+7+15+15+5+5 大概两个半月
Update your browser to view this website correctly. Update my browser now