在Debian系Linux中,用于标识应用的启动文件.desktop file是位于/usr/share/applications目录下的,Gnome会将这些文件在菜单中展示为启动图标,也可以固定在docker bar。
打开/usr/share/applications,可以看到有很多的.desktop文件,每一个文件就对应菜单中的一个启动图标。
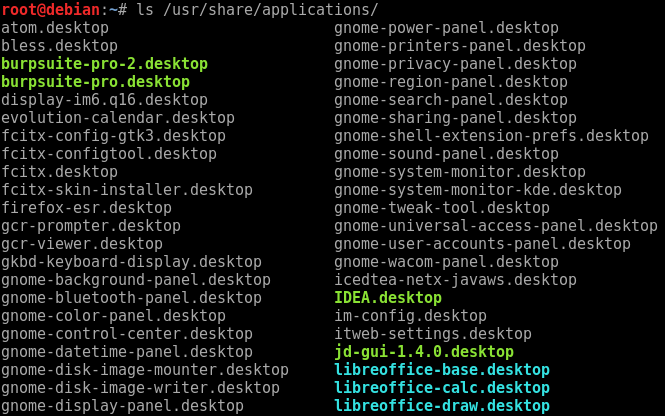
如何手动编辑和制作这样一个.desktop文件呢,这里以IDEA集成开发环境为例。
我的IDEA安装在/opt/idea-IC-182.4505.22/目录,IDEA的启动脚本是/opt/idea-IC-182.4505.22/bin/idea.sh。打开/opt/idea-IC-182.4505.22/目录,还可以看到IDEA的图标文件/opt/idea-IC-182.4505.22/bin/idea.png。
所以我们在/opt/idea-IC-182.4505.22/目录下创建IDEA.desktop文件,内容如下:
1 | [Desktop Entry] |
再将IDEA.desktop通过软链接添加到/usr/share/applications目录即可。
1 | ls -s /opt/idea-IC-182.4505.22/IDEA.desktop /usr/share/applications/IDEA.desktop |
再次打开菜单,即可看见创建的启动图标。如果看不到,可以先注销,再重新登录即可。
再分享两个常用的.desktop文件:
burpsuite(可用在kali上)
1 | [Desktop Entry] |
JD-GUI
1 | [Desktop Entry] |
